Как собрать максимальное количество профилей кандидатов на Stack Overflow
stackoverflow, сорсинг, R, кандидаты, поиск, профили
Почему не возможно собрать всю базу профилей кандидатов
В своей практике часто использую Stack Overflow в качестве “точки входа” для поиска кандидатов. Пользователи по разному относятся к данному ресурсу. Часть из них создают личный профиль, но через некоторое время забрасывают его и перестают пользоваться ресурсом. Другие, наоборот, продолжают активно участвовать и пишут ответы на вопросы пользователей или задают свои. Для нас могут быть полезными обе категории пользователей. Для наглядности приведу отрывок сообщения, который мне прислал кандидат.
“Мой профиль на SO заброшен уже года три как и не особо актуален. Просто нет времени на тамошнее кармодрочерство.”.
В процессе жизни у каждого человека меняется отношение к тем или иным явлениям - это нормально, для нас рекрутеров важно то, что человек оставил о себе след и у нас есть шанс установить с ним связь.
В данной статье покажу как можно использовать скрипт stackexchange и R для получения максимального количества профилей кандидатов. Кроме метода stackexchange существуют и другие методы поиска, которые вы можете найти в различных источниках, или в моей онлайн книге “Записки рекрутера”. Однако давайте ещё раз вспомним все основные методы поиска на Stack Overflow для того что бы лучше понять что меня не устраивает в них и что я предлагаю для преодоления препятствий.
Первый, и пожалуй самый традиционный, метод поиска профилей кандидатов является x-ray и boolean search. Отличные инструменты которыми легко и просто пользоваться. Однако всех ли кандидатов можно найти с помощью этих инструментов? Поиск осуществляется через поисковые системы google или duckduckgo и это является как большим преимуществом, так и коварным недостатком. Преимущество в том, что у google самая большая поисковая база по Stack Overflow. Если вы ищете как что-то сделать или избавиться от какой-либо проблемы, то google обязательно будет искать подобный вопрос на Stack Overflow. Но с другой стороны нам не известно как google обрабатывает результаты запросов поэтому в выдачу могут попасть не релевантные профили пользователей.
Второй метод - это поиск по карьерным страницам на Stack Overflow. Возможно этим методом нужно пользоваться самым первым, когда вы начинаете работать над новым пректом. Достоинство этого метода в том что рекрутер получает прямой доступ к контактной информации кандидатов. Согласитесь это важное преимущество. Однако и у этого метода есть свои недостатки. Главный из них - это относительно не большая база карьерных страниц.
Третий метод - это поиск с помощью сриптов data.stackexchange.com. Данный метод, на мой взгляд самый эффективный т.к. он позволяет собрать профили пользователей напрямую из базы Stack Overflow без каких-либо посредников. И поисковая выдача, как правило получается большой и с релевантными профилями. Однако, как известно “дьявол кроется в деталях”. Недостаток в том, что поиск осуществляется строго в рамках ключевых слов. Другими словами, какие ключевые слова введёте в поиск, то вы и получите в результате. Например, для поискового робота различные сочетание ключевых слов из стека и местоположения: vue.js, vuejs2, Россия и Russia будут разными и выдача будет отличаться. А теперь представьте, что вам необходимо найти разработчиков в Санкт-Петербуге. Интересно, сколько вариантов написания города вы сможете придумать? Давайте сверим: S-Petersburg, Saint Petersburg, Sankt-Peterburg, Санкт-Петербург, St. Petersburg, Saint-Petersburg, St Petersburg, Sankt-Peterburg, Питер, Piter. Итого 10 вариантов написания одного города России, но это не точно т.к. скорее всего есть варианты которые я пока не обнаружил. И как быть в этой ситуации? По очереди запускать поиск с одним или двумя главными стеками в сочетании с каждым вариантом написания города? Хорошо! А как быть с дублирующими профилями? А что делать есть нужно искать не только по Санкт-Петербургу, но и Москве? А если по всей России? Вы можете ответить, что для поиска по России достаточно указать местоположение Россия, Russia или Russian Federation. Да вы выберете от 70% до 90% возможных пользователей. Оставшихся пользователей вы снова упустите только потому, что они в своих профилях указали только город или географический район. Например, Moscú, Innopolis или frozen tundra или же просто не указали своё место положение. Чуть позже мы увидим, что большинство не указывают город или страну проживания.
Собираем профили по максимуму
Для максимального охвата профилей пользователей предлагаю использовать специальный срипт data.stackexchange.com, а так же R для обработки результатов выдачи.
Прежде чем приступить к поиску зайдём на страницу тегов в Stack Overflow https://stackoverflow.com/tags/synonyms и выберем два тега по которым будем искать профили кандидатов. Это важно т.к. необходимо точно знать как правильно пишутся технологии на сайте. Для примера возьму angularjs и vue.js
Для поиска профилей будем использовать следующий скрипт https://data.stackexchange.com/stackoverflow/query/1173863/search-resume-multiple-tags. Открываем страницу в браузере, в поля Skill1 и Skill2 вводим названия технологий и нажимаем Run Query. В результате получаем выдачу с общим результатом 18 796 строк профилей пользователей. На первый взгляд может показаться, что огромный результат который трудно обработать. Однако для обработки данных есть язык программирования R и RStudio в качестве IDE для удобства работы с данными. Из первоначальной таблицы выберем все профили, в которых указан регион проживания Россия и сохраним их в одну таблицу, а затем выберем те профили в которых не указано место нахождения. Предлагаю эти профили так же рассматривать т.к. среди них могу оказаться граждане из России.
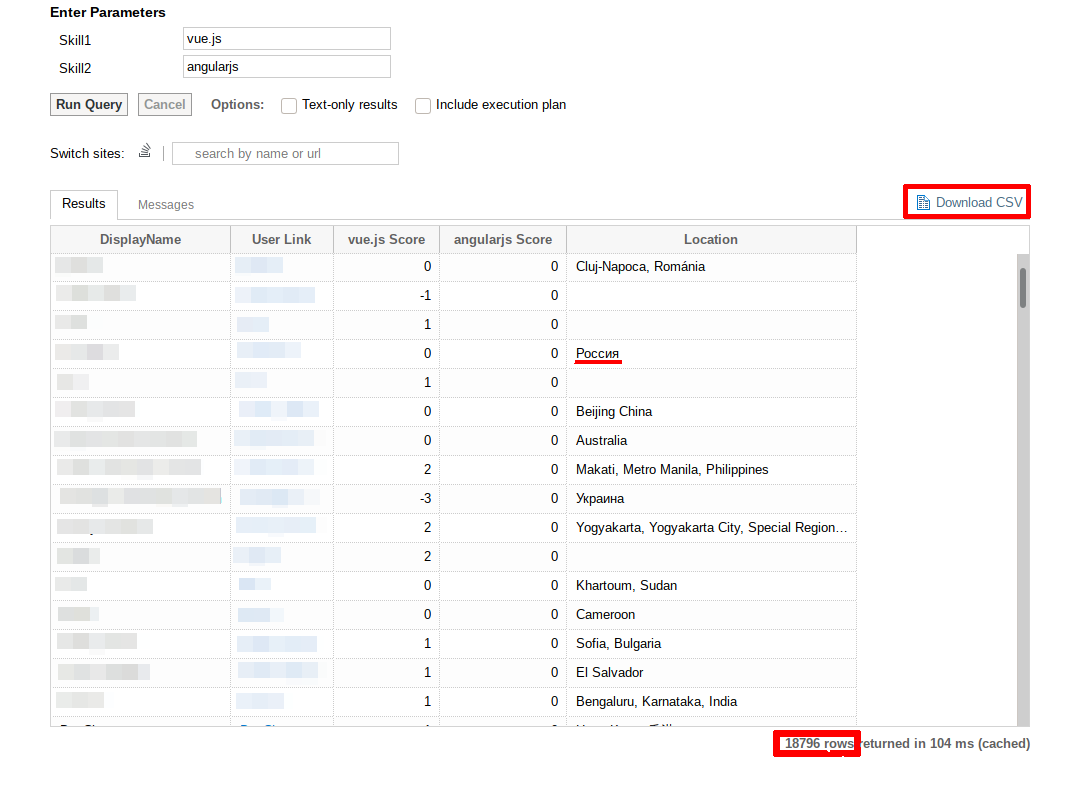
Нажимаем на “Download CSV” и скачиваем файл на Рабочий Стол компьютера. Открываем RStudio и делаем последовательно, простые операции.
# Устанавливаем пакет tidyverse, если он у вас не установлен.
install.packages("tidyverse")
# Активируем пакет
library(tidyverse)
# Переходим в директорию Рабочего стола
setwd("~/Рабочий стол")
# Загружаем данные из файла в R
tb <- read_csv('QueryResults.csv')
# Обработаем данные и привидём в удобный вид.
# Для начала выберем 3 (три) столбца DisplayName, Profile Link и Location, остальные столбцы нам не пригодятся.
# Сгруппируем новые данные по столбу Location.
# Отфильтруем построчно все строки через столбец Location, в которых будут встречаться список названий России и городов.
# В заключении сохраним новые данные в новой таблице tb1.
tb1 <- tb %>%
select(DisplayName, 'Profile Link', Location) %>%
group_by(Location) %>%
filter(Location %in% c("Russia", "Россия", "S-Petersburg, Russia", "Saint Petersburg, Russia", "Moscow, Russia", "Москва, Россия", "Moscow", "Москва",
"Новосибирск, Russia", "Belgorod, Russia", "Sankt-Peterburg, Санкт-Петербург, Россия", "Krasnoyarsk, Russia", "St. Petersburg, Russia",
"Novosibirsk, Novosibirsk Oblast, Russia", "Moscow, Россия", "Russia, Vladivostok", "Russian Federation", "Perm, Россия", "Russia, Ryazan",
"Yekaterinburg, Russia", "Samara, Россия", "Yekaterinburg, Россия", "Vladivostok, Russia", "Rostov-on-Don, Russia",
"Kaliningrad, Калинингадская область, Russia", "Cheboksary, Chuvashia Republic, Russia", "Kaliningrad, Kaliningrad Oblast, Russia",
"Russia, Chelyabinsk", "Vladimir, Russia", "Saratov, Russia", "frozen tundra", "Novocherkassk, Ростовская область, Россия",
"Khabarovsk, Russia", "Krasnoyarsk, Russia", "Kaliningrad, Калининградская область, Россия", "Нижний Новгород, Нижегородская область, Россия",
"Novokuznetsk, Россия", "Kazan', Russia", "Краснодар, Краснодарский край, Россия", "Saint-Petersburg", "Tobolsk, Russia", "Saint Petersburg, Россия",
"Krasnodar, Russia", "Irkutsk, Russia", "Novosibirsk, Russia", "Тверь, Россия", "Siberia, Novosibirsk", "Omsk, Russia",
"Yekaterinburg, Свердловская область, Россия", "Nizhnij Novgorod, Нижегородская область, Russia", "Moscou, Russie", "Saratov, Россия",
"Lipetsk, Россия", "Novosibirsk, Россия", "Rostov-na-Donu, Russia", "St Petersburg, Saint Petersburg, Russia", "Sankt-Peterburg, Russia",
"Tomsk, Russia", "Vladivostok, Primorsky Krai, Russia", "Kursk, Russia", "Innopolis, Tatarstan, Russia", "Владивосток, Приморский край, Россия",
"Rostov, Ростовская область, Россия", "Volgograd, Volgograd Oblast, Russia", "Samara, Самарская область, Russia", "Russia, Ufa",
"Russia, Краснодарский край, Россия", "Russia, Saint-Petersburg", "Ekaterinburg, Russia", "Люберцы, Россия", "Новосибирск, Россия",
"Orel, Oryol Oblast, Russia", "Simferopol', Крым", "Moskva, город Москва, Россия", "Tula, Тульская область, Россия",
"Москва, город Москва, Россия", "Moskva, Москва, Россия", "Кемерово, Кемеровская область, Россия", "Russia, Saint Petersburg",
"Norilsk, Россия", "Barnaul, Россия", "Ekaterinburg, Sverdlovsk oblast, Rusland", "Tomsk, Томская область, Россия", "Samara, Russia",
"Krasnoyarsk, Krasnoyarskiy kray, Russia", "Moskow, Rusia", "Kazan, Россия", "Penza, Russia", "Киров, Кировская область, Россия",
"Chelyabinsk, Russia", "Moscow Oblast, Russia", "Ufa, Россия", "Красноярск, Россия", "Ryazan', Рязанская область, Россия",
"Ulyanovsk, Russia", "Khabarovsk, Россия", "Moscow, Москва, Россия"))
# Снова возьмём исходные данные, скачанные с Stack Overflow.
# Повторим отбор столбцов и группирование новых данных, но в новую таблицу отфильтруем только те строки, у которых в столбце Location ничего не указано.
# Сохраним новые данные в таблицу tb0.
tb0 <- tb %>%
select(DisplayName, 'Profile Link', Location) %>%
group_by(Location) %>%
filter(is.na(Location))
# Объединим таблицы tb1 и tb0 в общую таблицу tb2.
# Сохраним таблицу tb2 в файл so_profiles.csv .
tb2 <- rbind(tb1, tb0)
write_csv(tb2, "so_profiles.csv")В результате у меня получилось отобрать 6677 профилей пользователей. Из них 6389 профилей без указания местоположения и 288 профиля из России. Понимаю, хочется что бы итоговые результаты поменялись местами, но с другой стороны вы теперь видите сколько профилей выпадают из нашего поиска и мы их другими методами найти и обнаружить не в состонии.
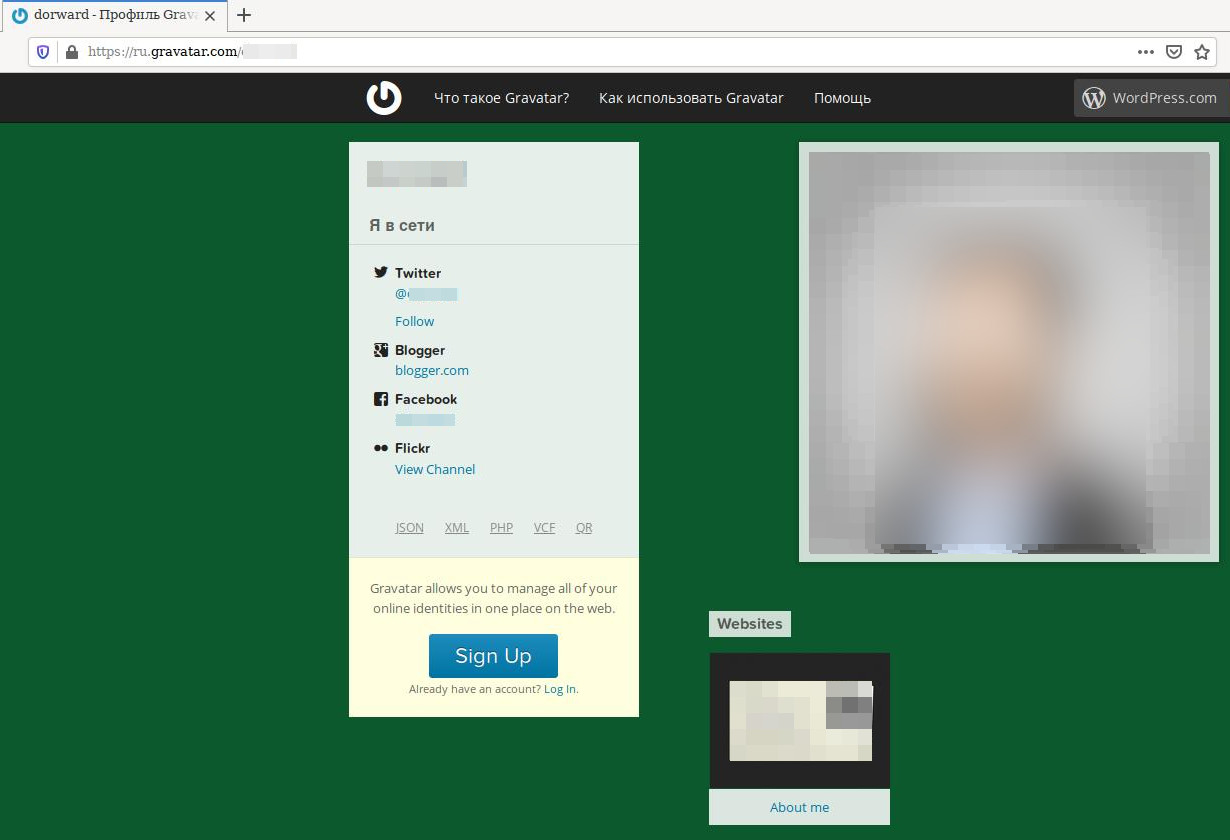
В заключение хотелось бы поделиться маленьким, но приятным бонусом. Когда открываете профиль пользователя на Stack Overflow, настоятельно рекомендую открывать изображение профиля. Повторяйте за мной.
Итак заходим в профиль пользователя и правой кнопкой мыши кликаем по изображению. В меню выбираем “Открыть изображение”.
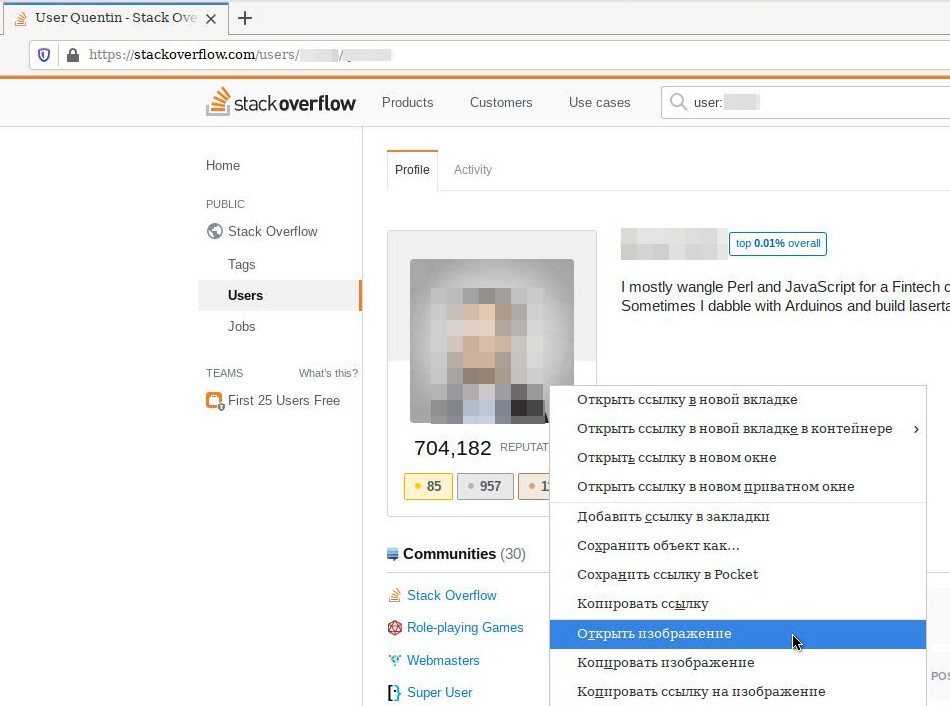
Далее вы увидите пустой экран, так и должно быть. Обратите внимание на url страницы. Он выглядит так.
https://www.gravatar.com/avatar/рандомные_числа?s=328&d=identicon&r=PG
Удаляем слово “avatar” из url так что бы в итоге получился новый адрес страницы как здесь.
https://www.gravatar.com/рандомные_числа?s=328&d=identicon&r=PG
И вуа ля перед нами дополнительная информация и контактные данные.