Кластерный анализ вакансий и резюме
кластерный анализ, данные, резюме, вакансии, график, статистика
Статья посвящена кластерному анализу, собранных мною данных количества вакансий и резюме с работного сайта HeadHunter. Обработка и анализ данных будет проводиться из открытых источников, поэтому при желании каждый может повторить анализ данных на своём компьютере. Код, написанный на R так же доступен в моём репозитории на GitHub, поэтому можете использовать для обработки и анализа собственных данных. Ссылка на репозиторий в конце статьи.
Главной задачей, которая была поставлена мною, заключается в том, что бы выявить, т.е. кластеризовать данные по двум векторам. Первый вектор - это кластеризация по параметрам вакансии/резюме - города (Москва, Санкт-Петербург, Новосибирск, республика Татарстан, Калужская и Томская области). Второй вектор - кластеризация по профессиональным областям: административный персонал, автомобильный бизнес, банки и финансы, рабочий персонал, управление персоналом и т.п. всего 28 профессиональных области. Цель заключается в том, что бы кластеры по двум векторам идентифицировать, проанализировать, описать и выдвинуть дальнейшие гипотезы. Ценность анализа в том, что бы данные в дальнейшем рассматривать ни как набор случайных данных, а как набор кластеров, которые можно описать и дать характеристики. В моём примере векторы представлены набором данных под названием data1 - первый вектор и data2 - второй вектор. В связи с этим выдвинем несколько гипотез. Нулевая гипотеза говорит о том, что ни по одному вектору данные не кластеризуемы. Гипотеза один свидетельствует о том, что по обоим векторам данные кластеризуемы. Гипотеза два - в любом одном из векторов данные формируются в кластеры.
Полная процедура кластерного анализа состоит из 7и этапов. Этап 1 - сбор данных, этап 2 - подготовка данных для вычислений, этап 3 - оценка тенденции к кластеризации, этап 4 - вычисление и визуализация дистанции между переменными, этап 5 - сравнение алгоритмов кластеризации, этап 6 - вычисление оптимального количества кластеров, этап 7 - кластеризация и визуализация кластеров. В завершении сделаем небольшой вывод полученных результатов.
Этап 1. Сбор данных
Данные скачаю с GitHub. После скачивания вы можете обнаружить, что скачались и другие файлы и папки, для работы они нам не понадобятся поэтому просто удалим их. Кроме этого хочу вас предупредить, что расчёты проводились на Fedora 27 x86_64, R version 3.4.4, поэтому если вы пользователь OC Windows или Apple, то вам необходимо будет скорректировать некоторые параметры.
# Скачаем данные с GitHub
setwd("~/Рабочий стол")
d <- download.file( url = "https://github.com/Dmitryi/statistic/archive/master.zip", destfile = "statistic.zip")
proc.time() - d
file.info("statistic.zip")
unzip(zipfile = "statistic.zip")
setwd("statistic-master")
list.files()
# Удалим не нужные файлы и папки
files.to.delete <- dir("~/Рабочий стол/statistic-master", pattern = ".*", recursive=F, full.names=T)
file.remove(files.to.delete)
unlink(c("css", "fonts", "img", "js"), recursive = TRUE)
# Переходим в папку с данными
setwd("data")
list.files()Этап 2. Подготовка данных для вычислений
После удаления ненужных файлов и папок мы переместились в папку “data”, в которой лежат необходимые нам файлы. Создадим две таблицы (data.frame) с которыми будет производить манипуляции. Для этого потребуется выгрузить часть информации из исходных файлов. Это нам позволит создать data1 и data2. Обратите внимание на отличия между data1 и data2.
Для data1 данные мы суммируем по столбцам т.е. складываем переменные по каждому столбцу “Вакансии Москва”, “Вакансии Санкт-Петербург”, “Резюме Москва”, “Резюме Санкт-Петербург”, “Вакансии Новосибирск”, “Резюме Новосибирск”, “Вакансии Татарстан”, “Вакансии Калужская обл.”, “Вакансии Томская обл.”, “Резюме Татарстан”, “Резюме Калужская обл.”, “Резюме Томская обл.” из всех исходных файлов: admin, banki, sales, tek, top и т.д. Аналогичную процедуру производим для data2, но отличие в том, что переменные суммируются по профессиональным областям: административный персонал; банки, инвестиции; безопасность; бухгалтерия; строительство; консалтинг; искусство, культура; государственная служба; домашний персонал; управление персоналом; инсталяция; ит, интернет; транспорт; маркетинг; медицина; наука; производство; рабочий персонал; продажи; спорт; страхование; начало работы; ТЭК; высший персонал; туризм; туризм; юристы; автомобильный бизнес; закупки. После того как data1 и data2 созданы проводим стандартизацию данных.
Как я сказал ранее из файлов берутся не все данные подряд, а с 905 строчки и не все колонки. Столбец с датой исключен т.к. эти данные мешают и не предоставляют существенной информации для анализа. С 905 строчки выделены данные по причине того, что именно с данной строчки появились данные по республике Татарстан, Калужской и Томской областях. На момент написания статьи крайней строчкой была 1225, но т.к. данные обновляются ежедневно, то если вы хотите скачать данные и проанализировать, крайней строчкой будет уже другая и следовательно вам её нужно будет изменить. Изменил так же и название колонок с кирилицы на латиницу. Графики на латинице будут выглядеть более компактными и понятными.
# Извлечём необходимые данные
banki <- read.csv("databanki.csv", header=T, sep=",")[905:1225,2:13]
buhgalter <- read.csv("databuh.csv", header=T, sep=",")[905:1225,2:13]
bulding <- read.csv("databulding.csv", header=T, sep=",")[905:1225,2:13]
consult <- read.csv("dataconsult.csv", header=T, sep=",")[905:1225,2:13]
culture <- read.csv("dataculture.csv", header=T, sep=",")[905:1225,2:13]
admin <- read.csv("datadmin.csv", header=T, sep=",")[905:1225,2:13]
gos <- read.csv("datagos.csv", header=T, sep=",")[905:1225,2:13]
house <- read.csv("datahouse.csv", header=T, sep=",")[905:1225,2:13]
hr <- read.csv("datahr.csv", header=T, sep=",")[905:1225,2:13]
instal <- read.csv("datainstal.csv", header=T, sep=",")[905:1225,2:13]
it <- read.csv("datait.csv", header=T, sep=",")[905:1225,2:13]
logist <- read.csv("datalogist.csv", header=T, sep=",")[905:1225,2:13]
market <- read.csv("datamarket.csv", header=T, sep=",")[905:1225,2:13]
medicina <- read.csv("datamedicina.csv", header=T, sep=",")[905:1225,2:13]
nauka <- read.csv("datanauka.csv", header=T, sep=",")[905:1225,2:13]
proizvotstvo <- read.csv("dataproizvotstvo.csv", header=T, sep=",")[905:1225,2:13]
rab <- read.csv("datarab.csv", header=T, sep=",")[905:1225,2:13]
sales <- read.csv("datasales.csv", header=T, sep=",")[905:1225,2:13]
secure <- read.csv("datasecure.csv", header=T, sep=",")[905:1225,2:13]
sport <- read.csv("datasport.csv", header=T, sep=",")[905:1225,2:13]
strahovanie <- read.csv("datastrahovanie.csv", header=T, sep=",")[905:1225,2:13]
study <- read.csv("datastudy.csv", header=T, sep=",")[905:1225,2:13]
tek <- read.csv("datatek.csv", header=T, sep=",")[905:1225,2:13]
top <- read.csv("datatop.csv", header=T, sep=",")[905:1225,2:13]
turizm <- read.csv("dataturizm.csv", header=T, sep=",")[905:1225,2:13]
urist <- read.csv("dataurist.csv", header=T, sep=",")[905:1225,2:13]
auto <- read.csv("datauto.csv", header=T, sep=",")[905:1225,2:13]
zakupki <- read.csv("datazakupki.csv", header=T, sep=",")[905:1225,2:13]
# Создадим 2а набора данных. В 1ый data.frame - data1 сложим сумму значений каждой профессиональной области по всем городам
# Во 2ой data.frame - data2 обьединим данные каждого города по каждой профессиональной области отдельно.
# Обьедим данные в один data frame
data1 <- (banki + buhgalter + bulding + consult + culture + admin + gos + house + hr + instal + it + logist + market + medicina +
nauka + proizvotstvo + rab + sales + secure + sport + strahovanie + study + tek + top + turizm + urist + auto + zakupki)
# Переименуем столбцы
library(dplyr)
data1 <- rename(data1, Vac.Moscow = Вакансии.Москва, Vac.SPb = Вакансии.Санкт.Петербург, Res.Moscow = Резюме.Москва, Res.SPb = Резюме.Санкт.Петербург,
Vac.Novosib = Вакансии.Новосибирск, Res.Novosib = Резюме.Новосибирск, Vac.Tatarstan = Вакансии.Татарстан, Vac.Kaluga = Вакансии.Калужская.обл,
Vac.Tomsk = Вакансии.Томская.обл, Res.Tatarstan = Резюме.Татарстан, Res.Kaluga = Резюме.Калужская.обл, Res.Tomsk = Резюме.Томская.обл)
# Для 2го data2 для начала вычислим сумму в каждой отдельной колонки, по отдельности в каждой проф. области, а так же добавим название строк
# проф. области и обьединим в один data.frame
banki <- banki %>% summarise_all(funs(sum))
rownames(banki) <- "banki"
buhgalter <- buhgalter %>% summarise_all(funs(sum))
rownames(buhgalter) <- "buhgalter"
bulding <- bulding %>% summarise_all(funs(sum))
rownames(bulding) <- "bulding"
consult <- consult %>% summarise_all(funs(sum))
rownames(consult) <- "consult"
culture <- culture %>% summarise_all(funs(sum))
rownames(culture) <- "culture"
admin <- admin %>% summarise_all(funs(sum))
rownames(admin) <- "admin"
gos <- gos %>% summarise_all(funs(sum))
rownames(gos) <- "gos"
house <- house %>% summarise_all(funs(sum))
rownames(house) <- "house"
hr <- hr %>% summarise_all(funs(sum))
rownames(hr) <- "hr"
instal <- instal %>% summarise_all(funs(sum))
rownames(instal) <- "instal"
it <- it %>% summarise_all(funs(sum))
rownames(it) <- "it"
logist <- logist %>% summarise_all(funs(sum))
rownames(logist) <- "logist"
market <- market %>% summarise_all(funs(sum))
rownames(market) <- "market"
medicina <- medicina %>% summarise_all(funs(sum))
rownames(medicina) <- "medicina"
nauka <- nauka %>% summarise_all(funs(sum))
rownames(nauka) <- "nauka"
proizvotstvo <- proizvotstvo %>% summarise_all(funs(sum))
rownames(proizvotstvo) <- "proizvotstvo"
rab <- rab %>% summarise_all(funs(sum))
rownames(rab) <- "rab"
sales <- sales %>% summarise_all(funs(sum))
rownames(sales) <- "sales"
secure <- secure %>% summarise_all(funs(sum))
rownames(secure) <- "secure"
sport <- sport %>% summarise_all(funs(sum))
rownames(sport) <- "sport"
strahovanie <- strahovanie %>% summarise_all(funs(sum))
rownames(strahovanie) <- "strahovanie"
study <- study %>% summarise_all(funs(sum))
rownames(study) <- "study"
tek <- tek %>% summarise_all(funs(sum))
rownames(tek) <- "tek"
top <- top %>% summarise_all(funs(sum))
rownames(top) <- "top"
turizm <- turizm %>% summarise_all(funs(sum))
rownames(turizm) <- "turizm"
urist <- urist %>% summarise_all(funs(sum))
rownames(urist) <- "urist"
auto <- auto %>% summarise_all(funs(sum))
rownames(auto) <- "auto"
zakupki <- zakupki %>% summarise_all(funs(sum))
rownames(zakupki) <- "zakupki"
data2 <- rbind(banki, buhgalter, bulding, consult, culture, admin, gos, house, hr, instal, it, logist, market, medicina, nauka, proizvotstvo,
rab, sales, secure, sport, strahovanie, study, tek, top, turizm, urist, auto, zakupki)
data2 <- rename(data2, Vac.Moscow = Вакансии.Москва, Vac.SPb = Вакансии.Санкт.Петербург, Res.Moscow = Резюме.Москва, Res.SPb = Резюме.Санкт.Петербург,
Vac.Novosib = Вакансии.Новосибирск, Res.Novosib = Резюме.Новосибирск, Vac.Tatarstan = Вакансии.Татарстан, Vac.Kaluga = Вакансии.Калужская.обл,
Vac.Tomsk = Вакансии.Томская.обл, Res.Tatarstan = Резюме.Татарстан, Res.Kaluga = Резюме.Калужская.обл, Res.Tomsk = Резюме.Томская.обл)
# Удалим строки с пропущенными значениями, если это необходимо
# data1 <- na.omit(data1)
# data2 <- na.omit(data2)
# Стандартизируем данные
library(cluster)
data1 <- scale(data1)
data2 <- scale(data2)Этап 3. Оценка тенденции к кластеризации
С данного этапа переходим в область выявления кластеров, но перед этим необходимо произвести несколько важных процедур. Для начала проведём оценку данных (data1 и data2) тенденции или склонности к кластеризации. Это важная процедура т.к. она позволит нам понять из наших данных возможно сформировать какие-либо кластеры или нет. Оценку будем проводить 2-мя способами - статистическим и визуальным. Статистический способ заключается в вычислении числа Хопкинса. Визуальный способ - в сравнении двух графиков. Первый график из набора данных, который у нас имеется второй из данных случайно сгенерированных.
# Вычислим значение Хопкинса - статистический метод оценки
# data1
library(factoextra)
get_clust_tendency(data1, n = nrow(data1)-1, graph = F)
# Сравним наши с данные со аналогичной по структуре данными, но случайно сгенерированными - визуальный метод оценки
set.seed(123)
random_data1 <- apply(data1, 2, function(x){runif(length(x), min(x), max(x))})
random_data1 <- as.data.frame(scale(random_data1))
get_clust_tendency(random_data1, n = nrow(random_data1) -1, graph = F)
fviz_dist(dist(t(data1)), show_labels = T)+
labs(title = "Данные вакансий кол-ва вакансий/резюме по городам")
fviz_dist(dist(random_data1), show_labels = F)+
labs(title = "Набор данных случайно сгенерированных")
# data2
get_clust_tendency(data2, n = nrow(data2)-1, graph = F)
set.seed(123)
random_data2 <- apply(data2, 2, function(x){runif(length(x), min(x), max(x))})
random_data2 <- as.data.frame(scale(random_data2))
get_clust_tendency(random_data2, n = nrow(random_data2) -1, graph = F)
fviz_dist(dist(data2), show_labels = T)+
labs(title = "Данные вакансий кол-ва вакансий и резюме по проф.областям")
fviz_dist(dist(random_data2), show_labels = FALSE)+
labs(title = "Набор данных случайно сгенерированных")Обращаю ваше внимание!
Число Хопкинса должно быть больше 0,5. В моём случае для data 1 $hopkins_stat = 0.04589563, для data2 $hopkins_stat = 0.2547937. Это означает, что по статистическому методу наши данные не имеют тенденции к группированию. На основе визуального метода оценки, можно сделать аналогичный вывод. Сравните графики данных data1, data2 (слева), с графиками случайно сгенерированных данных - random_data1, random_data2 (справа). Вы видите, что на последних графиках (случайно сгенерированных данных) наклонная линия нулевых значений очень четко видна и ярко выражена по сравнению с графиками данных data1 и data2, на которых эта линия не четкая. Следовательно гипотеза 0 оказалась более достоверной, чем гипотеза 1 и 2.
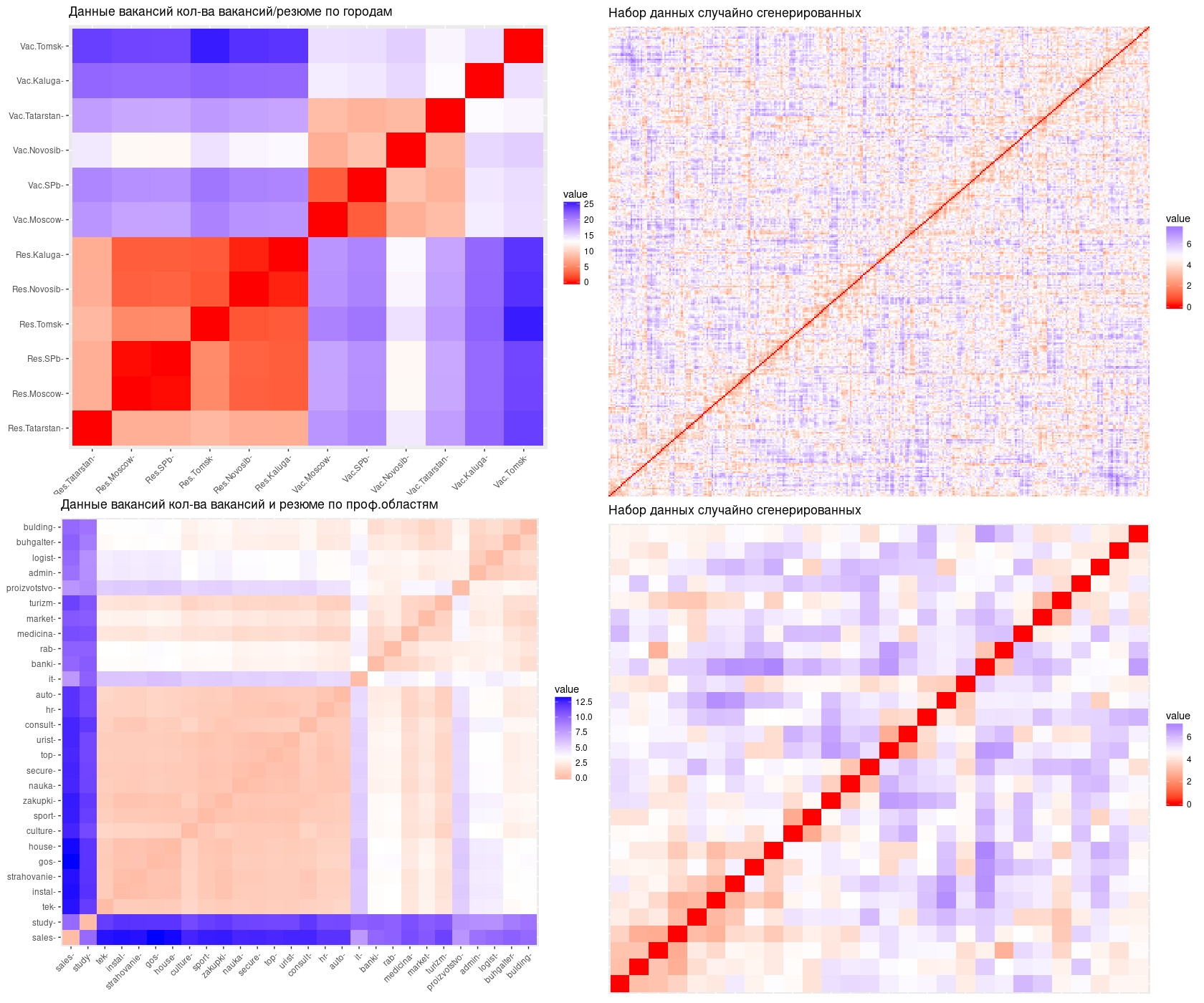
В связи с этим мы можем сделать вывод о том, что дальнейшие процедуры кластерного анализ можно рассматривать в качестве примера для анализа других данных. Несмотря на то, что оба метода убедительно свидетельствуют о том, что data1 и data2 не склонны к группированию данных я продолжу выполнять все процедуры, более того у меня даже получится выявить кластеры. Однако по другим признакам мы увидим, что кластеры сформированы в силу особенностей пакетов, которые их высчитывают. А именно пакеты так написаны, что если есть данные, то значит кластеры должны быть выделены в любом случае. Хочу добавить, что в математике кластерный анализ является нерешенной задачей. Для более глубокого понимания и изучения проблем кластерного анализа вы можете почитать в соответствующей литературе.
Этап 4. Вычислим и визуализируем дистанцию между переменными
Для расчёта дистанции я использовал метод Спирмена т.к. он более устойчив к выбросам. Но вы для своего проекта можете выбрать другой метод расчёта дистанции.
# Методы: "matching", "rogers", "jaccard.pa", "sorenson", "kulkczynski.pa", "ochiai", "gower", "steinhaus", "kulkczynski.q",
# "jaccard.q", "euclidean", "rel.euclidean", "manhattan", "czekanows", "pearson", "maximum", "canberra", "binary", "kendall",
# "spearman", "minkowski"
res.dist1 <- get_dist(t(data1), stand = TRUE, method = "spearman")
fviz_dist(res.dist1,
gradient = list(low = "#82ccb9", mid = "#5db6f7", high = "#d8effe"))
res.dist2 <- get_dist(data2, stand = TRUE, method = "spearman")
fviz_dist(res.dist2,
gradient = list(low = "#82ccb9", mid = "#5db6f7", high = "#d8effe"))На графике можно увидеть некоторые области закрашены зелёным цветом, который указывает на то, что расстояние между переменными близка или равна нулю. Следовательно, если между переменными расстояния нет - это означает, что либо кластеров вообще не возможно выделить, либо все данные представляют и входят в один большой кластер.
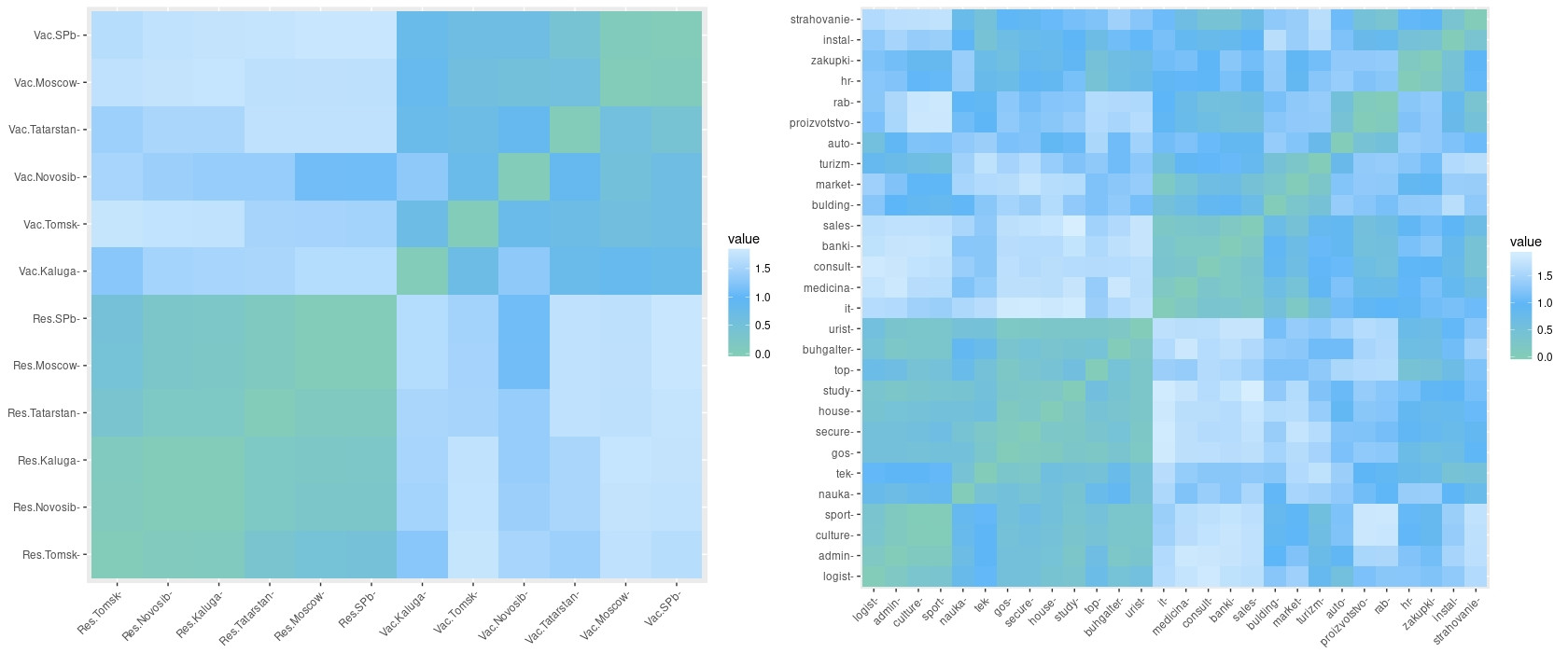
Этап 5. Сравнение алгоритмов кластеризации
Ещё одним важным этапом является вычисление оптимального алгоритма. Тем более если учесть, что структура данных может меняться, следовательно и алгоритм для расчета кластеров необходимо выполнять каждый раз иначе может появиться ошибка, как следствие кластеры могут быть не правильно подсчитаны и решение будет принято не верно.
# methods: "hierarchical", "kmeans", "diana", "fanny", "som", "model", "sota", "pam", "clara", "agnes"
# validation: "internal", "stability", "biological"
library(clValid)
clmethods <- c("hierarchical","kmeans","pam")
data1_stab <- clValid(data1, nClust = 2:10,
clMethods = clmethods, validation = "stability")
optimalScores(data1_stab)
clmethods <- c("hierarchical","kmeans","pam")
data2_stab <- clValid(data2, nClust = 2:10,
clMethods = clmethods, validation = "stability")
optimalScores(data2_stab)На изображении видно, что для data1 оптимальный алгоритм является “pam” (PAM означает «разделение вокруг медоидов». Алгоритм предназначенный для поиска последовательности объектов, называемых медойдами которые расположены в центре в кластеров). Для data2 оптимальным алгоритмом является “hierarchical” (Иерархическая кластеризация). Одна важная деталь количество кластеров очень сильно разница от 2 до 10, другими словами оптимальный алгоритм рассчитан, но каково количество кластеров должно быть, неизвестно!

Этап 6. Рассчитаем оптимальное количество кластеров
Перед тем как перейти к заключительному этапу мы должны рассчитать оптимальное количество кластеров, на которые должны быть поделены переменные. Для определения количества кластеров будем использовать 4 метода. Первый - метод Локтя, второй - метод Силуэта, третий - метод статистики пробелов, четвертый - методика расчёта по 30 индексам.
# Метод Локтя
# kmeans, pam, clara, hcut
library(NbClust)
fviz_nbclust(data1, pam, method = "wss") +
geom_vline(xintercept = 4, linetype = 2)+
labs(subtitle = "Метод Локтя")
fviz_nbclust(data2, hcut, method = "wss") +
geom_vline(xintercept = 4, linetype = 2)+
labs(subtitle = "Метод Локтя")
# Метод Силуэта
fviz_nbclust(data1, pam, method = "silhouette")+
labs(subtitle = "Метод Силуэта")
fviz_nbclust(data2, hcut, method = "silhouette")+
labs(subtitle = "Метод Силуэта")
# Метод статистики пробелов
set.seed(123)
fviz_nbclust(data1, pam, method = "gap_stat", nboot = 500)+
labs(subtitle = "Метод статистики пробелов")
fviz_nbclust(data2, hcut, method = "gap_stat", nboot = 500)+
labs(subtitle = "Метод статистики пробелов")
# Методика расчёта по 30ти индексам для выбора наилучшего количества кластеров
# distance: "euclidean", "manhattan", "NULL"
# method: "ward.D", "ward.D2", "single", "complete", "average", "kmeans"
nb_data1 <- NbClust(data1, distance = "euclidean", min.nc = 2,
max.nc = 10, method = "complete")
fviz_nbclust(nb_data1)
nb_data2 <- NbClust(data2, distance = "euclidean", min.nc = 2,
max.nc = 10, method = "complete")
fviz_nbclust(nb_data2)
# Для лучшей наглядности повернём data1, колонски сделаем строками и сохраним подназванием data3
data3 <- t(data1)
# Визуализация кластеров
set.seed(123)
km.res <- kmeans(data3, 10)
fviz_cluster(km.res, data = data3,
ellipse.type = "euclid",
palette = "cos2",
star.plot = TRUE,
repel = TRUE,
main = "Визуализация кластеров по резюме/вакансиям-городам",
ggtheme = theme_minimal())
km.res <- kmeans(data2, 3)
fviz_cluster(km.res, data = data2,
ellipse.type = "euclid",
palette = "Dark1",
star.plot = TRUE,
repel = TRUE,
main = "Визуализация кластеров по проф. областям",
ggtheme = theme_minimal())Для data2 оптимальное количество кластеров будет 3 т.к. в двух методиках из 4х это число стало оптимальным количеством кластеров. А для data1 выберем 10 кластеров т.к. метод статистики пробелов наиболее надёжный.
| Метод | Результаты расчётов для data1 | Результаты расчётов для data2 |
|---|---|---|
| Метод Локтя | 4 кластера | 4 кластера |
| Метод Силуэта | 3 кластера | 2 кластера |
| Метод статистики пробелов | 10 кластеров | 3 кластера |
| Методика по 30ти индексам | 2 кластера | 3 кластера |
Ниже графики визуализации кластеров. Как можете видеть кластеров по вектору вакансии/резюме - города не сформированы, а точнее почти каждый из критериев представляет собой кластер. По второму вектору кластеры сформированы. Однако здесь важно отметить, что 3 кластер, который состоит из двух проф. областей продажи и начало карьеры, скорее всего представляют собой выбросы, а не кластеры.
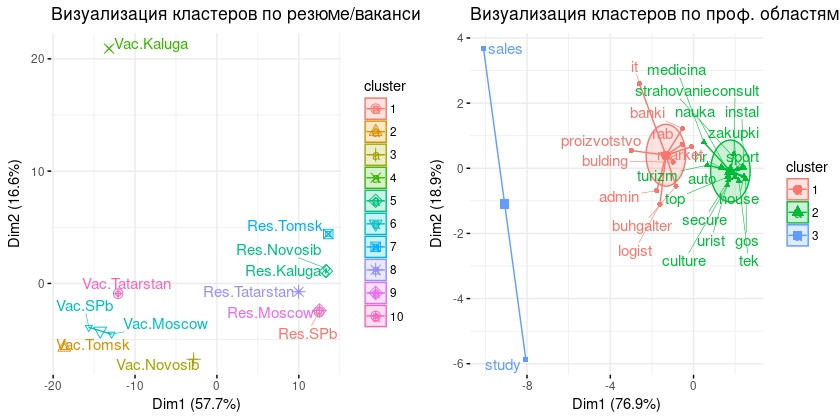
Этап 7. Кластеризация
На предыдущем этапе, по сути, уже выполнили кластерный анализ, однако исследование будет не полным если не выявить кластеры и другими методами. Мы можем выполнить иерархическую кластеризацию, нечёткую или не жесткую кластеризацию, кластеризацию на основе моделей и кластеризацию по плотности. Внизу, после кода, представлю графики, слева data1, справа data2.
# Иерархическая кластеризация
library("igraph")
dend1 <- dist(data3) %>%
hclust(method = "ward.D2")
fviz_dend(dend1, k = 10, k_colors = "jco", main = "data1",
type = "phylogenic", repel = TRUE)
dend2 <- dist(data2) %>%
hclust(method = "ward.D2")
fviz_dend(dend2, k = 3, k_colors = "jco", main = "data2",
type = "phylogenic", repel = TRUE)
# Нечёткая кластеризация
data1_fanny <- fanny(data1, 10) # Вычислить нечеткую кластеризацию, цифра - кол-во кластеров
fviz_cluster(data1_fanny, ellipse.type = "norm", repel = TRUE,
palette = "Set3", ggtheme = theme_classic(),
legend = "right")
fviz_silhouette(data1_fanny, palette = "Set3",
ggtheme = theme_bw())
data2_fanny <- fanny(data2, 3)
fviz_cluster(data2_fanny, ellipse.type = "norm", repel = TRUE, main = "data2",
palette = "Accent", ggtheme = theme_classic(),
legend = "right")
fviz_silhouette(data2_fanny, palette = "Accent",
ggtheme = theme_bw())
# Кластеризация на основе моделей
library(mclust)
mc1 <- Mclust(data1)
summary(mc1)
mc1$modelName # Оптимальная выбранная модель
mc1$G # Оптимальное число кластеров
head(mc1$z, 30) # Вероятность принадлежать данному кластеру
head(mc1$classification, 30) # Кластерное назначение каждого наблюдения
fviz_mclust(mc1, "BIC", palette = "Dark2") # Значения BIC, используемые для выбора количества кластеров
fviz_mclust(mc1, "classification", repel = TRUE, main = "data1", # Классификация: график, показывающий кластеризацию
pointsize = 1.5, palette = "Dark2")
fviz_mclust(mc1, "uncertainty", repel = TRUE, palette = "Dark2", main = "data1") # Неопределенность классификации
mc2 <- Mclust(data2)
summary(mc2)
mc2$modelName # Оптимальная выбранная модель
mc2$G # Оптимальное число кластеров
head(mc2$z, 30) # Вероятность принадлежать данному кластеру
head(mc2$classification, 30) # Кластерное назначение каждого наблюдения
fviz_mclust(mc2, "BIC", palette = "Paired") # Значения BIC, используемые для выбора количества кластеров
fviz_mclust(mc2, "classification", repel = TRUE, main = "data2", # Классификация: график, показывающий кластеризацию
pointsize = 1.5, palette = "Paired")
fviz_mclust(mc2, "uncertainty", repel = TRUE, palette = "Paired", main = "data2") # Неопределенность классификации
# Кластеризация по плотности
library(fpc)
library(dbscan)
# Определим значение eps - на графике соответствует резкому изгибу, MinPts должно быть не менее 3
dbscan::kNNdistplot(data3, k = 10)
abline(h = 2.5, lty = 2)
set.seed(123)
data1_fpc <- fpc::dbscan(data3, eps = 2.5, MinPts = 5)
fviz_cluster(data1_fpc, data = data3, stand = T, main = "data1",
ellipse = T, show.clust.cent = T, repel = F,
palette = "cos2", ggtheme = theme_minimal())
print(data1_fpc)
dbscan::kNNdistplot(data2, k = 3)
abline(h = 0.8, lty = 2)
set.seed(123)
data2_fpc <- fpc::dbscan(data2, eps = 0.8, MinPts = 5)
fviz_cluster(data2_fpc, data = data2, stand = T, main = "data2",
ellipse = T, show.clust.cent = T,
repel = TRUE, palette = "PiYG", ggtheme = theme_minimal())
print(data2_fpc)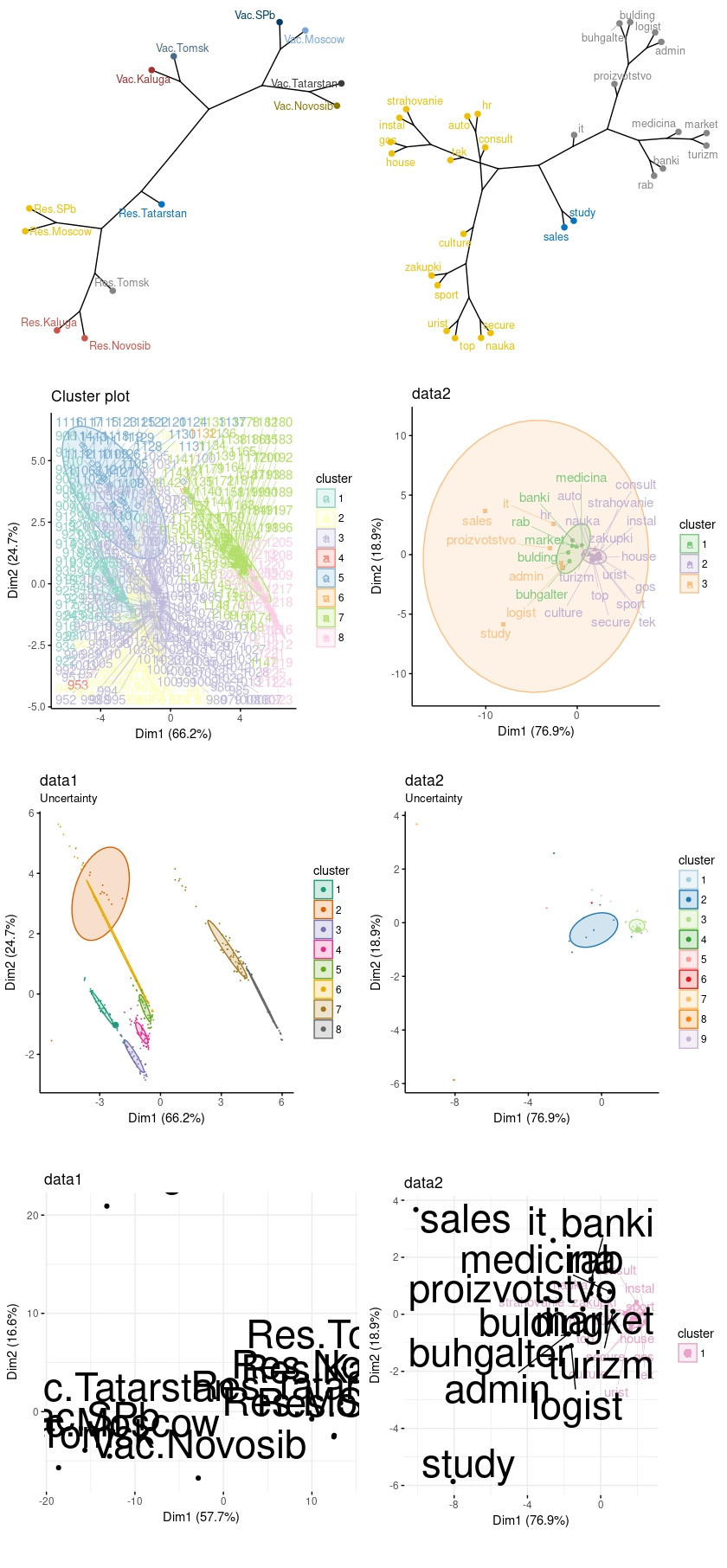
Выводы
Не смотря на то, что не удалось достоверно получить результаты о кластерах в наших данных, можно допустить два предположения. Первое - кластеры не удалось получить по причине ограниченности данных, т.е. данных объективно мало. Второе - диапазон критериев слишком маленький для выявления кластеров. Второе предположение относится к данным data1. Другими словами если мы возьмём данные не по 3 городам, одной республике и 2 областям, а по 50 городам, например, то с высокой долей вероятности можно предположить, что кластеры проявятся. А для data2 возможно верно первое предположение - данных слишком мало для того что бы можно было рассчитать кластеры.
Ссылка на GitHub
Используемые источники:
1. https://www.statmethods.net/
2. http://www.sthda.com/
3. https://www.youtube.com/channel/UC0YHNueF-3Nh3uQT0P4YQZw
4. https://ranalytics.github.io/data-mining/index.html
5. https://stackoverflow.com/
6. https://github.com/kassambara/factoextra