Источники получения данных
Статистика зарплат специалистов и конкурентов на рынке труда, для работодателей является востребованным и актуальным предметом постоянного внимания. Более того за изменением рынка зарплат следят не только работодатели, но сотрудники. Таким образом обозначая две противостоящих друг другу общественно-социальных энергий. Каждая из этих “энергий” старается добиться более благоприятных условий для себя, решить собственные задачи и разрешить противоречия. Статистические наблюдения за экономической ситуацией, а так же за рынком труда и изменением зарплатных предложений (работодателей) и ожиданий (кандидатов), могут позволить выдвинуть предположение о том какая из “энергий” находится в наиболее благоприятных условиях. Получить данные по зарплатным ожиданиям и предложениям можно двумя способами. Первый - это организовать и провести опрос среди кандидатов, что чаще всего, а так же опросить работодателей. Второй способ - это собрать данные из отрытых источников в интернете. Проводить опросы среди кандидатов и среди работодателей долго, сложно и затратно. А если результаты опросов публикуются открыто, то перепроверить достоверность довольно сложно. Что касается второго способа, то он также довольно трудозатратный, но при этом более контролируемый. Хотя существует вопрос о методологии сбора информации. Для сбора данных часто используются скрипты и парсеры, но в данной статье хочу обратить ваше внимание на ряд моментов, которые ускользают при автоматизации сбора данных. Данная статья - это попытка показать и доказать, что ручной сбор данных может быть более качественным, а следовательно статистика более объективная, а принятое решение более взвешенным.
Ручной и автоматический сбор данных
В современной практике менеджмента управления персонала перед тем как приступить непосредственно к поиску кандидатов, проводится анализ рынка зарплат. Рассмотрим популярную ситуацию, когда сбор данных и анализ проводится собственными силами сотрудников организации. Сотрудники hr отделов самостоятельно или при поддержке ИТ отдела проводят сбор данных по зарплатным ожиданиям и предложениям из различных открытых источников. И если ещё вчера основным и единственным в качестве источника данных являлись работные сайты, то сегодня добавились социальные сети и специлизированные телеграм каналы и чаты. Объём значительно вырос и первое что приходит на ум в качестве решения - это специальные скрипты или парсеры, которые автоматически собирают нужную информацию. На первый взгляд правильное и логичное решение. Автоматизация позволяет за короткое время обработать огромный массив информации и отобрать только нужные данные. Например, на github собрано достаточно примеров различных парсеров под различные задачи и платформы, позволяющие собирать любую информацию. С технической точки зрения я не вижу больших проблем для рекрутеров самостоятельно проводить парсинг данных не прибегая к поддержке ит отдела или разработчиков. На самом деле возможно вам понадобится помощь со стороны аналитиков. Кроме того что бы собрать данные их нужно привести к единому стандарту и подготовить для вычислений. Сами вычисления простые, но данные из всех источников и от всех респондентов должны быть единообразными и стандартными. В этом плане аналитики вам лучше помогут с форматом записей данных, их хранением и визуализацией. Хотя и в этом случае можно обратиться к многочисленным книгам и видео лекциям, урокам и докладам в интернете для того что бы изучить язык R или Python, о том как можно организовать хранилище данных, какие данные существуют и как их структурировать. На первом этапе вам необходимо изучить несколько библиотек и стандартных команд для для сбора и очистки данных. Далее по мере того как заказчики начнут проявлять интерес к статистике, запросы будут более точными и конкретными это потребует от вас более серьёзного планирования и проведения сбора данных, но расти в процессе проще, когда опираешься на базовые инструменты. Таким образом я хочу ещё раз обратить ваше внимание на методологические и организационные проблемы связанные со статистикой зарплат, а не технические. Не смотря на возросший объём информации и объективно увеличившихся площадок автоматизация возможна и она не такая сложная как может показаться. На мой взгляд специалисту в области управления персоналом, который готов отвечать из аналитику в hr отделе важнее понимать о чём говорят цифры, что за ними стоит и о чём они могут сказать, а о чём нет. Вас как профессионала будут ценить не за то что вы можете собрать данные из интернета, и сделать красивые графики, а за то что можете предложить варианты решения задач, поможете выработать стратегию найма персонала, и снизить риски. А для этого нужно видеть данные и понимать их природу. Понимать какой смысл вкладывают сами кандидаты или работодатели в то что они предоставляют. И снова возвращаюсь к первоначальной мысли - ручной сбор данных имеет важное преимущество перед автоматическим, а именно - контроль над данными и понимание природы этих данных.
Что нужно знать про статистику зарплат
Уверен, что вы уже не раз видели или обращали внимание на различного рода исследования, публикации или дашборды с данными по зарплатам. Как правило это графики, иногда в качестве переменных используются регионы или языки программирования. В качестве публичного обсуждения “общей температуры по больнице” такого рода визуализации данных вполне подходят, но для корпоративной статистики нет. По двум причинам. Во-первых, как правило у нас нет исходных данных, поэтому мы не можем перепроверить данные или произвести дополнительные вычисления. Во-вторых, эти данные как правило носят общий характер. Например, статистика зарплат среди java разработчиков в Москве и в регионах. Хорошо, а сколько из них готовы работать в офисе? А сколько человек имеют стаж работы от 3 до 6 лет? А если для нас важно знание какой-либо технологии или опыт работы в игровой индустрии?! Данные по зарплаты сами по себе красивые, но они бесполезные если мы не понимаем как мы можем их проанализировать. Именно поэтому во внутренних корпоративных исследованиях сбор данных проводится целенаправленно и сразу по нескольким параметрам.
Данные по зарплатам
На первый взгляд кажется, что может быть проще чем записать зарплатные ожидания кандидатов в таблицу. И вы будете правы как правило кандидаты указывают зарплаты в рублях и цифры округлены. Однако, что если в резюме указана вилка зарплат? Какую цифру следует записывать в таблицу? Есть три варианта: минимальную, максимальную и среднее значение. В своей практике я записываю максимальную по той причине, что кандидат всегда будет стремиться получить максимальную зарплату. Кроме зарплаты в рублях некоторые кандидаты указывают желаемую зарплату в иностранной валюте других государств. А теперь представьте кандидат рассчитывает на 1000 долларов США, курс доллара на момент когда я пишу статью составляет 90 руб. 41 копейка соответственно в рублях составит 90410 руб. Понятно, что цифру лучше округлить, но в какую сторону? Можно округлить до 90000, а можно до 91000. Да я в курсе про правила округлений в математике, но вторая цифра не такая уж не реалистичная. Курс валют постоянно меняется и когда в резюме стоит цифра 5000 USD или 7000 EUR и т.д. то округление в большую сторону в нарушение правил не кажется чем-то бессмысленным. То же самое относится к ситуации когда в вакансии от конкурирующей компании указана вилка зарплат. Может быть работодатель и хотел бы платить меньше, но кандидаты будут ориентироваться на максимальную зарплату. Мы сейчас разобрались с зарплатами специалистов, которые рассматривают работу на полную занятость с трудоустройством в штат. А как быть с теми кто ищет работу с почасовой оплатой? Представьте, что заказчик просит собрать статистику зарплат по специалистам с постоянной занятостью и с почасовой оплатой. На самом деле всё остаётся прежним, но заказчику следует задать вопрос почему возникло такое желание и объяснить, что данные будут разделены, а аналитика будет представлена отдельно для каждой категории кандидатов.
Офис, удалёнка или гибрид
На примере хэдхантера рассмотрим как мы можем определить готов кандидат работать в офисе или рассматривает только удалённый вариант. Проблема состоит в том, что в фильтрах хэдхантера нет пунктов работа в офисе или гибридный график, но есть пункт удалённая работа. Хедхантер и другие работные сайты ориентированы на трудовой кодекс, в котором нет понятия работа в офисе, поэтому и в фильтрах нет такого пункта.
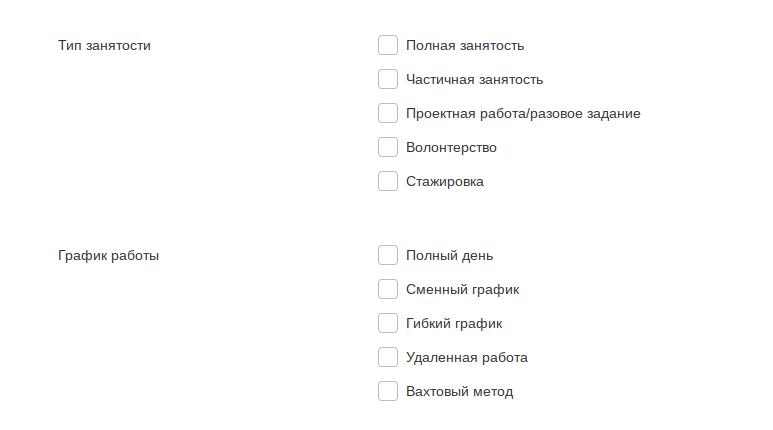
Однако на практике постоянно приходится работать с данным фильтром и для себя пришёл к следующему решению. Если в резюме кандидат указывает или пишет, что рассматривает только удалённую работу, значит ставлю единицу в столбце “удалёнка”. Даже если указаны пункты “Полная занятость” и “Полный день”. Если где либо в резюме кандидат пишет, что рассматривает гибридный график работы, пусть даже с удалённой работой, как на скриншоте ниже, то единицу записываю в столбец “гибридный график”. Я понимаю, что кандидат возможно более заинтересован работать удалённо, но что очень важно у работодателя есть шанс нанять такого сотрудника, который будет 2-3 дня работать в офисе.

Кандидаты, которые в резюме указывают пункты “Полная занятость” и “Полный день”, без пунктов “Удалённая работа”, я отношу к тем кто готов работать в офисе. Следовательно единицу записываю в столбец “офис”. И здесь логика простая - кандидат ни как не обозначил, что он ищет удалённую работу или с гибридным графиком. Кроме этого кандидат готов работать стандартный восьмичасовой рабочий день, пять дней в неделю. А предыдущий опыт работы в резюме кандидата подсказывает, что и до этого он или она работал(а) в офисе.
Стаж работы и профессиональные грейды
Для определения уровня квалификации кандидатов, в корпоративном языке закрепились такие понятия как джун (Junior), мидл (Middle), сеньор (Senior), тим лид (Team Lead). К сожалению аналоги данных грейдов в русском языке не прижились, хотя каждому из них можно дать более осмысленное название. Например, джуна можно переименовать в начинающего или молодого специалиста, мидла в самостоятельного, сеньора - профессионала, тим лида - руководителя. Однако важнее то, что на работных сайтах отсутствуют фильтры по грейдам, но есть фильтры по стажу работы. На скриншоте виден фильтр по требуемому опыту работы. Обращаю ваше внимание, он относится к общему стажу работы, а не к отдельной профессиональной деятельности.

Исходя из стажа работы я сопоставляю следующим образом: Нет опыта - джун; От 1 года до 3 лет - мидл; От 3 до 6 лет - сеньор; Более 6 лет - Тим лид. Согласен, что такое разделение условно и не всегда соответствует реальности, но в подавляющем большинстве случаев развитие карьеры сотрудников развивается в заданных интервалах. Кроме этого сами работодатели в свох вакансиях ориентируются на такое же соответствие грейдов и стаж работы. Общий стаж учитывает совокупный опыт работы за всю профессиональную карьеру. Однако мы знаем, что человек может менять профессиональную деятельность в своей карьере. Например, кандидат несколько лет работал системным администратором, а последние год работает в качестве DevOps инженера или Python разработчик ищет работу на должность Data Science. И здесь возникают ещё более интересные трудности с тем к какому грейду относить резюме того или иного кандидата, а именно зарплату (цифру) в какой столбец следует записать? В своей практике зарплату таких специалистов записываю в столбец джуны. Дело в том, что как бы близки не были профессиональные сферы обучаться новому всё равно придётся, следовательно такой специалист не будет полностью самостоятельным и его работу кто-то будет контролировать. И уж тем более такого специалиста трудно назвать профессионалом. Для коллег опыт в смежной области является плюсом, но не достаточным в новой профессиональной деятельности. Возможно вы подумали, что в данном случае зарплату можно не записывать в данные. Однако это не лучшее решение и вот почему, во-первых, часто бывает так, что данных не достаточно поэтому приходится работать с тем что есть. Во-вторых, не стоит бояться того что у кандидатов с опытом, которые переходят в другую область, зарплатные ожидания выше, чем у студентов, которые закончили институт. В заключительном разделе “Подсчитываем и визуализируем” я покажу как подсчитываю данные. И в-третьих, данные специалисты есть и мы не можем их игнорировать ради “красивых и приятных” цифр и графиков. Для того что бы быстрее ускорить сбор данных и главное ничего не перепутать, рекомендую использовать данный фильтр и сортировать резюме по опыту работы как указано на скриншоте. Например, сначала ставлю галочку в чекбоксе пункта “Нет опыта”, собраю данные в таблицу, цифры с зарплатами записываю в столбец “Джун”, затем ставим галочку в чекбоксе “От 1 года до 3 лет”, а галочку в пункет “Нет опыта” убираю. Данные записываю в столбец “Мидл” и так с остальными данными. Аналогичным образом поступаем при сборе данных из вакансий.

Навыки и технологии
Для начала хочу сразу предупредить, что с данным параметром редко имею дело поэтому ограничусь коротким абзацем. Дело в том, что часть навыков и технологий имеют устоявшиеся и общепризнанные названия, а некоторые имеют несколько названий. Кроме этого всегда нужно помнить, что название технологий могут быть написаны в кириллической транскрипции. Это имеет значение в двух моментах. Во-первых, когда в фильтрах мы указываем название технологий кириллическими и латинскими буквами, мы больше получаем охват аудитории, следовательно данных можем собрать больше. Во-вторых, очень важно соблюдать полярность между выборкой данных из резюме и данными из вакансий. Работодатели могут называть одну и ту же технологию или навыки разными названиями и это важно учитывать.
Регионы
Данный фильтр приходится использовать постоянно поэтому вам придётся обращать внимание на то что вы указали в данном фильтре, когда собираете данные на хэдхантере. Обратите внимание на скриншот - фильтр по регионам в таком виде существует только для резюме кандидатов. Поэтому когда вы будете использовать этот фильтр вы должны чётко понимать данные каких кандидатов вас интересуют или другими словами выборку из каких кандидатов вы готовы рассматривать на вакансию. А так же, как я писал выше, необходимо соблюдать полярность между вакансиями и резюме, выборки должны совпадать не просто по названию региона, но и по смыслу. Например, заказчик говорит, что кандидата ищем для работы в московском офисе, но готовы рассмотреть из регионов, при условии, что кандидат готов к переезду. С точки зрения сбора данных это означает, что для выборки резюме в качестве региона указываем Москва и Московская область, а также пункт “Живут в указанном регионе или готовы переехать в него”. А вот для выборки вакансий мы будем смотреть только из регионов Москва и Московская область.
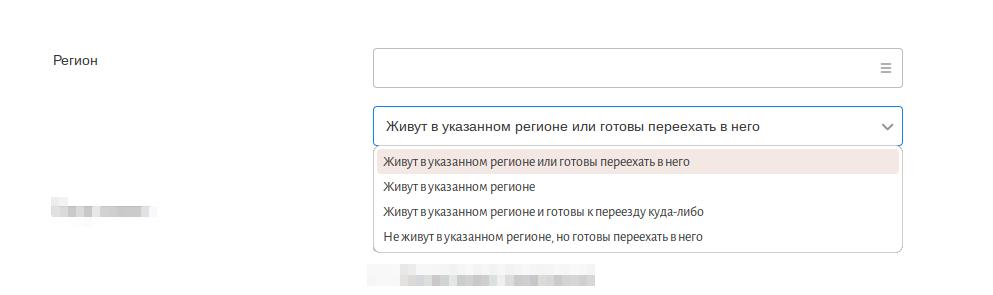
Отлично, фильтр настроили так как нам необходимо. Теперь, перед тем как записывать цифру зарплаты из резюме необходимо убедиться, что человек действительно проживает в том регионе который нам необходим. Некоторые из кандидатов из других стран пишут регион проживания Москва, но при этом учебное заведение и организации, в которых он работает и/или работал указаны другой страны. Если я вижу такое резюме, то данные не записываю. Скорее всего такой кандидат находится в другой стране, где он учился и работал. Проблема в том, что такой кандидат слабо себе представляет что значит жить в другой стране, а следовательно его ожидания по зарплате не отражают той возможной действительности в новом регионе с которой ему придётся столкнуться.
Подсчитываем и визуализируем
Перед тем как перейти к заключительной теме. Хочу ответить на ваш вопрос, а как быть с данными из соц. сетей и телеграм каналов. Мой ответ простой - всё тоже самое, что и с работных сайтов. Только фильтры вы применить не сможете, но придётся читать резюме или вакансии полностью и размышлять. Например, готов кандидат к переезду или нет, рассматривает работу в офисе или на удалёнку или работодатель ищет мидла или сеньора и т.д. Фильтры вы уже понимаете поэтому на каждое резюме и вакансию их применяете. Однако ничего не додумывайте за работодателя или кандидата, опирайтесь только на факты, указанные в объявлении.
Теперь, что касается представления результатов статистики. В своей практике пользуюсь гугл таблицами и без визуализации. Но вы можете делать отчёты так принято или как желает заказчик. То что я описал выше относится только к сбору данных, но когда данные собраны, подсчитаны и оформлены в таблицу, то они интуитивно подсказывают выводы. Исходя из вышеперечисленных фильтров и параметров можно сделать простую таблицу. Все цифры условны!
| Должность | Мин. | Q1 | Медиана | Q3 | Макс. | Регион | Офис | Удалёнка | Гибрид |
|---|---|---|---|---|---|---|---|---|---|
| Джун | 10000 | 20000 | 30000 | 40000 | 50000 | Россия | 2 | 5 | 1 |
| Мидл | 20000 | 30000 | 40000 | 50000 | 60000 | Россия | 2 | 5 | 1 |
| Сеньор | 30000 | 40000 | 50000 | 60000 | 70000 | Россия | 2 | 5 | 1 |
| Тим Лид | 40000 | 50000 | 60000 | 70000 | 80000 | Россия | 2 | 5 | 1 |
График может быть полезен не только для наглядной презентации результатов, но и для того что бы посмотреть, например, выбросы. Кроме квартелей можно добавить столбец для средних значений или для наиболее часто встречающихся. Однако разбивка на квартили позволяет понять в какой части спектра находится зарплатное предложение вашей вакансии. И возможно пусть даже не значительная коррекция по зарплате повысит шансы на более быстрый найм нового сотрудника. Кроме этого выбросы, которые неизбежны для любой выборки не так сильно искажают общую картину по зарплатам.